- publication
- EUROGRAPHICS/ACM SIGGRAPH Symposium on Geometry Processing 2013
- authors
- Giorgio Marcias, Nico Pietroni, Daniele Panozzo, Enrico Puppo, Olga Sorkine-Hornung
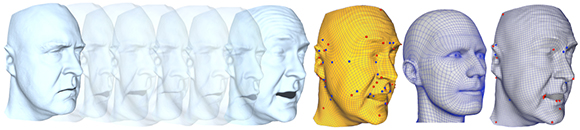
Given a sequence of triangle meshes sampling an animation, we produce a quadrilateral mesh that can fit all animation frames well (center, yellow). Our mesh better represents natural shape structures, just like meshes designed by artists (center-right), while a quadrangular mesh computed from a single pose with Mixed Integer Quadrangulation (right, grey) exhibits a more artificial structure. Colored dots highlight singularities of the quad meshes.
abstract
Geometric meshes that model animated characters must be designed while taking into account the deformations that the shape will undergo during animation. We analyze an input sequence of meshes with point-to-point correspondence, and we automatically produce a quadrangular mesh that fits well the input animation. We first analyze the local deformation that the surface undergoes at each point, and we initialize a cross field that remains as aligned as possible to the principal directions of deformation throughout the sequence. We then smooth this cross field based on an energy that uses a weighted combination of the initial field and the local amount of stretch. Finally, we compute a field-aligned quadrangulation with an off-the-shelf method. Our technique is fast and very simple to implement, and it significantly improves the quality of the output quad mesh and its suitability for character animation, compared to creating the quad mesh based on a single pose. We present experimental results and comparisons with a state-of-the-art quadrangulation method, on both sequences from 3D scanning and synthetic sequences obtained by a rough animation of a triangulated model.
downloads
- Paper (SGP 2013, official version available at http://diglib.eg.org/)
- Video
- BibTex entry
accompanying video
acknowledgments
We wish to thank the authors of [VBMP08] for making data of the Crane and Squat sequences available on the web (http://people.csail.mit.edu/drdaniel/mesh_animation/). We wish to thank the authors of [BHPS10] and [BHB∗11] for kindly providing the two face sequences. The research leading to these results is partly funded by the EU Community’s FP7 ICT under the V-MusT.net Project (Grant Agreement 270404), the SNF award 200021_137879, ERC grant iModel (StG-2012-306877) and a gift from Adobe Research.