- publication
- IEEE International Conference on 3D Vision (3DV) 2016
- received
- Best Paper Award at 3DV 2016
- authors
- Kaan Yücer, Changil Kim, Alexander Sorkine-Hornung, Olga Sorkine-Hornung
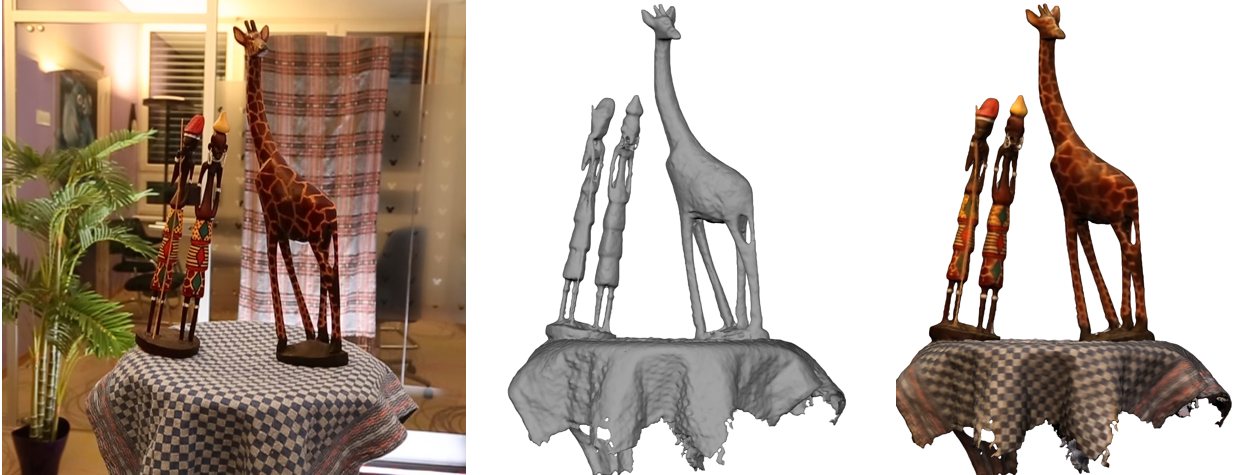
Given a dense light field around a foreground object, our technique reconstructs the object in 3D with its fine details. Left: An input view from the AFRICA dataset. Right: The reconstructed mesh rendered with and without the texture. Note the reconstructed details, such as the stick, the legs and the arms of the figurines.
abstract
Objects with thin features and fine details are challenging for most multi-view stereo techniques, since such features occupy small volumes and are usually only visible in a small portion of the available views. In this paper, we present an efficient algorithm to reconstruct intricate objects using densely sampled light fields. At the heart of our technique lies a novel approach to compute per-pixel depth values by exploiting local gradient information in densely sampled light fields. This approach can generate accurate depth values for very thin features, and can be run for each pixel in parallel. We assess the reliability of our depth estimates using a novel two-sided photoconsistency measure, which can capture whether the pixel lies on a texture or a silhouette edge. This information is then used to propagate the depth estimates at high gradient regions to smooth parts of the views efficiently and reliably using edge-aware filtering. In the last step, the per-image depth values and color information are aggregated in 3D space using a voting scheme, allowing the reconstruction of a globally consistent mesh for the object. Our approach can process large video datasets very efficiently and at the same time generates high quality object reconstructions that compare favorably to the results of state-of-the-art multi-view stereo methods.
downloads
errata
In the bottom part of Figure 3, the places of the magenta and blue dots should be switched.